DDD 充血模型概念解释
什么是充血模型?
在你的项目中,像 MessageId、UserId、ChatId 这样的类就是 DDD(领域驱动设计)中的值对象(Value Object),它们体现了充血模型的设计思想。
充血模型 vs 贫血模型
贫血模型(Anti-Pattern)
// 贫血模型:只有数据,没有行为
public class MessageEntity {
private String messageId; // 只是简单的 String
private String senderId; // 只是简单的 String
// ... 只有 getter/setter,没有业务逻辑
}充血模型(DDD 推荐)
// 充血模型:既有数据,又有行为和业务规则
public class MessageId extends BaseId {
private final String value;
public MessageId(String value) {
// 包含验证逻辑
if (value == null || value.trim().isEmpty()) {
throw new IllegalArgumentException("消息ID不能为空");
}
this.value = value;
}
// 提供业务方法
public static MessageId generate() {
return new MessageId(generateUUID());
}
public static MessageId of(String value) {
return new MessageId(value);
}
}为什么要这样设计?
1. 类型安全
// 贫血模型:容易混淆
public void sendMessage(String messageId, String userId, String chatId) {
// 很容易把参数顺序搞错!
service.send(userId, messageId, chatId); // 编译通过,但逻辑错误
}
// 充血模型:类型明确
public void sendMessage(MessageId messageId, UserId userId, ChatId chatId) {
// 参数类型不匹配,编译器会报错
service.send(userId, messageId, chatId); // 编译错误!
}2. 封装业务规则
public class MessageId extends BaseId {
public MessageId(String value) {
super(value);
// 在构造时就验证,确保所有 MessageId 对象都是有效的
validateFormat(value);
}
private void validateFormat(String value) {
if (!value.matches("^MSG_[A-Z0-9]{32}$")) {
throw new IllegalArgumentException("消息ID格式不正确");
}
}
}3. 表达领域概念
// 贫血模型:看不出业务含义
String id1 = "123";
String id2 = "456";
if (id1.equals(id2)) { ... } // 这两个 ID 是什么?用户ID?消息ID?
// 充血模型:清晰的业务语义
MessageId messageId = MessageId.of("MSG_123");
UserId userId = UserId.of("USER_456");
// messageId.equals(userId); // 编译错误,不同类型无法比较4. 不可变性(Immutability)
public class MessageId extends BaseId {
private final String value; // final 确保不可变
// 没有 setter 方法,创建后无法修改
// 这符合 ID 的本质:一旦生成就不应该改变
}5. 丰富的行为
public class UserId extends BaseId {
// 可以添加业务方法
public boolean isSystemUser() {
return value.startsWith("SYS_");
}
public boolean isAnonymous() {
return value.equals("ANONYMOUS");
}
}实际应用示例
// 在你的项目中
public class MessageEntity {
private MessageId messageId; // 不是 String,是值对象
private UserId senderId; // 不是 String,是值对象
private ChatId chatRoomId; // 不是 String,是值对象
// 业务方法可以利用值对象的行为
public boolean isSentBySystemUser() {
return senderId != null && senderId.isSystemUser();
}
public void markAsRead() {
// 充血模型:实体包含业务逻辑
this.status = "READ";
this.readTime = LocalDateTime.now();
this.updateTime = LocalDateTime.now();
}
}DDD 分层架构中的位置
┌─────────────────────────────────────┐
│ 应用层 (Application Layer) │
│ - 接收 String 类型的参数 │
│ - 转换为值对象传递给领域层 │
└─────────────────────────────────────┘
↓
┌─────────────────────────────────────┐
│ 领域层 (Domain Layer) │
│ - 使用值对象 (MessageId, UserId) │ ← 充血模型在这里
│ - 包含业务规则和验证 │
│ - 实体和值对象都有行为 │
└─────────────────────────────────────┘
↓
┌─────────────────────────────────────┐
│ 基础设施层 (Infrastructure Layer) │
│ - 将值对象转换为 String 存储 │
│ - 从数据库读取时转换回值对象 │
└─────────────────────────────────────┘总结
充血模型的核心思想是:让对象不仅包含数据,还包含操作这些数据的行为和业务规则。这样可以:
✅ 提高代码可维护性:业务规则集中在一处
✅ 增强类型安全:编译期就能发现错误
✅ 表达业务语义:代码更接近业务领域
✅ 减少重复代码:验证逻辑只写一次
✅ 提高代码质量:不可变对象更安全
这就是为什么你的项目中使用 MessageId、UserId 等值对象,而不是简单的 String 类型!
一行总结
所有继承自 BaseId 的值对象(如 PostId、UserId、MessageId 等)都使用 getValue() 方法获取内部的字符串值,而不是 getId()。
充血模型统一规范
在你的 DDD 项目中,所有 ID 值对象都遵循这个模式:
// BaseId 基类
public abstract class BaseId {
private final String value; // 字段名是 value
public String getValue() { // getter 方法是 getValue()
return value;
}
}
// 使用示例
PostId postId = PostId.of("POST_123");
String idString = postId.getValue(); // ✅ 正确
UserId userId = UserId.of("USER_456");
String userIdString = userId.getValue(); // ✅ 正确
MessageId messageId = MessageId.generate();
String msgIdString = messageId.getValue(); // ✅ 正确这样设计的好处是保持了统一的命名规范,所有值对象都通过 getValue() 获取内部值,代码更加一致和易读!
对比一下 MessageService 和 LikeEntity 的设计:两种设计模式的对比
好问题!这涉及到 DDD 中边界上下文(Bounded Context)和职责分离的设计原则。让我详细解释这两种不同的设计考量:
1️⃣ MessageService 的设计(领域服务层)
// MessageService.java - 领域服务
public MessageEntity createTextMessage(
String chatRoomId, // ✅ 接收原始 String
String senderId, // ✅ 接收原始 String
String receiverId, // ✅ 接收原始 String
String content
) {
// 在服务内部进行转换
MessageId messageId = MessageId.of(generateMessageId());
return MessageEntity.builder()
.messageId(messageId)
.chatRoomId(ChatId.of(chatRoomId)) // 转换
.senderId(UserId.of(senderId)) // 转换
.receiverId(UserId.of(receiverId)) // 转换
.build();
}设计理由:
🎯 服务层职责:负责协调和转换
🎯 便于调用:上层(应用层/API层)传入的通常是 String
🎯 封装转换逻辑:服务内部统一处理类型转换
2️⃣ LikeEntity 的设计(实体构造函数)
// LikeEntity.java - 领域实体
public LikeEntity(
String likeId,
UserId userId, // ✅ 直接要求值对象
PostId postId // ✅ 直接要求值对象
) {
this.userId = Objects.requireNonNull(userId, "用户ID不能为空");
this.postId = Objects.requireNonNull(postId, "帖子ID不能为空");
this.targetId = postId.getValue();
}设计理由:
🎯 实体职责:保证领域模型的完整性和一致性
🎯 类型安全:在编译期就确保传入的是正确的类型
🎯 明确依赖:清楚地表达实体需要什么类型的对象
🎯 防止错误:避免在实体内部做过多的转换逻辑
其实我在这里是想提问 Cursor:LikeEntity 和 MessageEntity 的设计区别, 在 MessageEntity 的构造函数定义都是属性,LikeEntity 的构造函数定义包含值对象?
为什么不能改成 PostId.of(String postId)?
你可以改,但不推荐。让我展示两种方案的对比:
❌ 方案A:实体接收 String(不推荐)
// 实体构造函数
public LikeEntity(String likeId, String userId, String postId) {
this.likeId = likeId;
this.userId = UserId.of(userId); // 实体内部转换
this.postId = PostId.of(postId); // 实体内部转换
this.targetId = postId;
}
// 调用方式
LikeEntity like = new LikeEntity("LIKE_123", "USER_456", "POST_789");问题:
1.❌ 实体承担了转换职责(违反单一职责原则)
2.❌ 类型不安全,容易传错参数顺序
3.❌ 失去了值对象的验证保护
4.❌ 调用者不知道这些 String 会被转换成什么
✅ 方案B:实体接收值对象(推荐,当前设计)
// 实体构造函数
public LikeEntity(String likeId, UserId userId, PostId postId) {
this.likeId = likeId;
this.userId = userId; // 直接使用
this.postId = postId; // 直接使用
this.targetId = postId.getValue();
}
// 调用方式(在服务层转换)
UserId userId = UserId.of("USER_456");
PostId postId = PostId.of("POST_789");
LikeEntity like = new LikeEntity("LIKE_123", userId, postId);优势:
1.✅ 类型安全,编译期检查
2.✅ 实体只关注业务逻辑,不关注转换
3.✅ 值对象的验证在创建时就完成了
4.✅ 代码意图清晰
完整的分层设计示例
让我展示一个完整的调用链,说明为什么这样设计:
// ========================================
// 1. API 层(接收 HTTP 请求)
// ========================================
@RestController
public class LikeController {
@PostMapping("/posts/{postId}/like")
public ResponseEntity<Void> likePost(
@PathVariable String postId, // HTTP 传入 String
@RequestHeader String userId // HTTP 传入 String
) {
// 调用应用服务
likeApplicationService.likePost(userId, postId);
return ResponseEntity.ok().build();
}
}
// ========================================
// 2. 应用层(协调服务)
// ========================================
@Service
public class LikeApplicationService {
public void likePost(String userIdStr, String postIdStr) {
// 在应用层进行转换
UserId userId = UserId.of(userIdStr);
PostId postId = PostId.of(postIdStr);
// 调用领域服务,传入值对象
likeDomainService.createLike(userId, postId);
}
}
// ========================================
// 3. 领域服务层(业务逻辑)
// ========================================
@Service
public class LikeDomainService {
public LikeEntity createLike(UserId userId, PostId postId) {
// 生成点赞ID
String likeId = generateLikeId();
// 创建实体,传入值对象(不是 String)
LikeEntity like = new LikeEntity(likeId, userId, postId);
// 保存到仓储
likeRepository.save(like);
return like;
}
}
// ========================================
// 4. 领域实体(核心模型)
// ========================================
public class LikeEntity {
// 接收值对象,保证类型安全
public LikeEntity(String likeId, UserId userId, PostId postId) {
this.userId = userId; // 已经是验证过的值对象
this.postId = postId; // 已经是验证过的值对象
}
}MessageService 为什么接收 String?
MessageService 是一个领域服务,它的职责包括:
public class MessageService {
// 这是一个工厂方法,负责创建消息实体
public MessageEntity createTextMessage(
String chatRoomId, // 接收 String 是为了方便上层调用
String senderId,
String receiverId,
String content
) {
// 1. 验证业务规则
validateTextMessage(content);
// 2. 生成ID
String messageId = generateMessageId();
// 3. 转换为值对象(服务层的职责)
MessageId msgId = MessageId.of(messageId);
ChatId chatId = ChatId.of(chatRoomId);
UserId sender = UserId.of(senderId);
// 4. 创建实体
return MessageEntity.builder()
.messageId(msgId)
.chatRoomId(chatId)
.senderId(sender)
.build();
}
}为什么这样设计?
🎯 服务是边界:它是外部世界(String)和领域模型(值对象)之间的桥梁
🎯 封装复杂性:上层不需要知道如何创建值对象
🎯 统一入口:所有创建消息的逻辑都在这里
最佳实践建议
✅ 推荐做法
// 1. 实体构造函数:接收值对象
public class LikeEntity {
public LikeEntity(String likeId, UserId userId, PostId postId) {
// 直接使用,不转换
}
}
// 2. 领域服务:接收 String,内部转换
public class LikeDomainService {
public LikeEntity createLike(String userIdStr, String postIdStr) {
// 服务层负责转换
UserId userId = UserId.of(userIdStr);
PostId postId = PostId.of(postIdStr);
// 传递值对象给实体
return new LikeEntity(generateId(), userId, postId);
}
}
// 3. 应用服务:协调调用
public class LikeApplicationService {
public void likePost(String userId, String postId) {
likeDomainService.createLike(userId, postId);
}
}总结
| 层次 | 接收类型 | 职责 | 原因 |
|---|---|---|---|
| API层 | String | 接收HTTP请求 | 外部传入的都是字符串 |
| 应用层 | String | 协调服务 | 简化调用,统一转换 |
| 领域服务 | String 或 值对象 | 业务逻辑协调 | 可以接收String并转换 |
| 领域实体 | 值对象 | 核心业务模型 | 类型安全,保证完整性 |
核心原则
- 实体构造函数应该接收值对象(如 PostId、UserId)
✅ 类型安全
✅ 职责清晰
✅ 编译期检查
- 服务层可以接收 String
✅ 便于上层调用
✅ 封装转换逻辑
✅ 统一入口
- 转换应该在服务层完成,而不是实体内部
✅ 单一职责
✅ 关注点分离
所以,LikeEntity 的当前设计是正确的,它接收 PostId 对象而不是 String,这是有意为之的良好设计!🎯
实例
关于LikeEntity和MessageEntity中MessageId 和 ChatId 设计
A:谢谢,其实我想问的是 @LikeEntity.java 和 @MessageEntity.java 中的 MessageId 和 ChatId,一般来说 我在定义一个 ID 值的时候,通常使用 String 或者 Long 类型来定义这个变量值,但是在这里却是定义的值对象,这属于是 DDD 里面哪种设计思路了,这样做的好处是什么,解决了什么问题,如果没有优势的话,那就是过度设计了
Q:非常好的问题!这确实是 DDD 中一个重要的设计决策。让我详细解释为什么要把 ID 设计成值对象,而不是简单的 String 或 Long。
这是 DDD 中的值对象(Value Object)设计模式
对比:原始类型 vs 值对象
让我用实际例子展示两种设计的差异:
❌ 使用原始类型(String/Long)
public class MessageEntity {
private String messageId; // 只是个 String
private String chatRoomId; // 只是个 String
private String senderId; // 只是个 String
private String receiverId; // 只是个 String
}
// 使用时的问题
public void sendMessage(String messageId, String senderId, String chatRoomId) {
// 问题1:参数顺序容易搞错,编译器无法检测
service.send(senderId, messageId, chatRoomId); // ❌ 顺序错了,但编译通过!
// 问题2:可以传入任何字符串
service.send("hello", "world", "123"); // ❌ 无效ID,但编译通过!
// 问题3:到处都是字符串验证
if (messageId == null || messageId.isEmpty()) { ... }
if (!messageId.matches("^MSG_[A-Z0-9]+$")) { ... }
// 每个使用的地方都要重复这些验证
}✅ 使用值对象(Value Object)
public class MessageEntity {
private MessageId messageId; // 明确的类型
private ChatId chatRoomId; // 明确的类型
private UserId senderId; // 明确的类型
private UserId receiverId; // 明确的类型
}
// 使用时的优势
public void sendMessage(MessageId messageId, UserId senderId, ChatId chatRoomId) {
// 优势1:类型安全,参数顺序错了编译器会报错
service.send(senderId, messageId, chatRoomId); // ✅ 编译错误!
// 优势2:无法传入无效值
MessageId id = MessageId.of("hello"); // ✅ 构造时就验证,抛出异常
// 优势3:验证只在一处
// MessageId 内部已经验证过了,使用时不需要再验证
}我自己补充一下 MessageId 是如何内部验证的
public class MessageId extends BaseId {
private static final long serialVersionUID = 1L;
/**
* 构造函数
*
* @param value 消息ID值
*/
public MessageId(String value) {
super(value);
}
******
/**
* 基础ID值对象
* <p>
* 所有业务ID的基类,提供统一的ID生成和验证机制
*
* @author alisunxin
* @version 1.0
*/
@Getter
@EqualsAndHashCode
public abstract class BaseId implements Serializable {
private static final long serialVersionUID = 1L;
/**
* ID值
*/
private final String value;
/**
* 构造函数
*
* @param value ID值
*/
protected BaseId(String value) {
if (value == null || value.trim().isEmpty()) {
throw new IllegalArgumentException("ID值不能为空");
}
this.value = value.trim();
}这样就一目了然了,只要是 ID 相关的值对象就集成 BaseId,使用 BaseId 的构造方法去验证值对象
值对象设计解决的核心问题
1️⃣ 原始类型偏执(Primitive Obsession) - 代码坏味道
这是 Martin Fowler 在《重构》一书中提到的经典代码坏味道。
// ❌ 原始类型偏执
public class OrderService {
public void createOrder(
String orderId, // 什么格式?多长?
String userId, // 和 orderId 有什么区别?
String productId, // 能传 userId 吗?编译器不知道
String price, // 是字符串?还是数字?
String currency // USD? CNY? 谁来验证?
) {
// 到处都是验证代码
if (orderId == null || !orderId.matches("^ORD_\\d+$")) {
throw new IllegalArgumentException("订单ID格式错误");
}
if (userId == null || !userId.matches("^USER_\\d+$")) {
throw new IllegalArgumentException("用户ID格式错误");
}
// ... 重复的验证代码
}
}
// ✅ 使用值对象
public class OrderService {
public void createOrder(
OrderId orderId, // 清晰的类型
UserId userId, // 不同的类型
ProductId productId, // 明确的语义
Money price, // 封装了金额和货币
Currency currency // 枚举或值对象
) {
// 不需要验证,值对象保证了有效性
// 编译器保证了类型安全
}
}2️⃣ 类型安全(Type Safety)
// ❌ String 类型:编译器无法帮你
public void transferMessage(String fromChatId, String toChatId, String messageId) {
// 可以这样调用,编译通过,但逻辑错误
transferMessage(messageId, fromChatId, toChatId); // 参数顺序错了!
}
// ✅ 值对象:编译器是你的朋友
public void transferMessage(ChatId fromChatId, ChatId toChatId, MessageId messageId) {
// 这样调用会编译错误
transferMessage(messageId, fromChatId, toChatId); // ❌ 类型不匹配!
}真实案例:
// 曾经的真实 Bug
public void sendNotification(String userId, String deviceId) {
// 开发者不小心写反了
pushService.send(deviceId, userId); // Bug!但编译通过
}
// 使用值对象后
public void sendNotification(UserId userId, DeviceId deviceId) {
// 写反了会立即报错
pushService.send(deviceId, userId); // ❌ 编译错误
}3️⃣ 封装业务规则(Business Rules Encapsulation)
// ❌ 业务规则散落各处
public class MessageService {
public void createMessage(String messageId) {
// 验证1:在这里验证
if (!messageId.startsWith("MSG_")) {
throw new IllegalArgumentException("消息ID必须以MSG_开头");
}
}
}
public class MessageRepository {
public void save(String messageId) {
// 验证2:又在这里验证一次(重复代码)
if (!messageId.startsWith("MSG_")) {
throw new IllegalArgumentException("消息ID必须以MSG_开头");
}
}
}
// ✅ 业务规则集中在值对象中
public class MessageId extends BaseId {
public MessageId(String value) {
super(value);
// 验证只在一处
if (!value.startsWith("MSG_")) {
throw new IllegalArgumentException("消息ID必须以MSG_开头");
}
}
// 一旦创建成功,就保证是有效的
}
// 使用时不需要验证
public class MessageService {
public void createMessage(MessageId messageId) {
// 不需要验证,messageId 保证是有效的
}
} 4️⃣ 表达业务概念(Ubiquitous Language)
DDD 强调使用通用语言(Ubiquitous Language),代码应该反映业务领域。
// ❌ String 无法表达业务含义
public void processPayment(String id1, String id2, String id3) {
// 这些 ID 是什么?需要看文档或注释
}
// ✅ 值对象清晰表达业务概念
public void processPayment(OrderId orderId, UserId userId, PaymentId paymentId) {
// 一眼就能看懂业务含义
// 这是业务专家和开发者都能理解的语言
}实际对话:
业务专家:"当用户点赞一个帖子时,我们需要记录用户ID和帖子ID"
// ❌ 技术实现偏离业务语言
public void like(String s1, String s2) { ... }
// ✅ 技术实现与业务语言一致
public void like(UserId userId, PostId postId) { ... }5️⃣ 不可变性(Immutability)
// ❌ String 可以被重新赋值
public class MessageEntity {
private String messageId;
public void setMessageId(String messageId) {
this.messageId = messageId; // ❌ ID 不应该改变!
}
}
// ✅ 值对象天然不可变
public class MessageId extends BaseId {
private final String value; // final 保证不可变
// 没有 setter 方法
// 一旦创建就不能改变
}为什么不可变很重要?
// 可变的 ID 会导致问题
MessageEntity msg = new MessageEntity();
msg.setMessageId("MSG_123");
cache.put(msg.getMessageId(), msg);
// 后来有人改了 ID
msg.setMessageId("MSG_456"); // ❌ 缓存中的键值对应关系被破坏了!
// 不可变的 ID 避免了这个问题
MessageId id = MessageId.of("MSG_123");
// id.setValue("MSG_456"); // ❌ 编译错误,没有这个方法6️⃣ 丰富的行为(Rich Behavior)
值对象不仅仅是数据容器,还可以包含行为。
// ❌ String 没有业务行为
public class MessageService {
public boolean isSystemMessage(String messageId) {
return messageId.startsWith("SYS_"); // 业务逻辑散落在外部
}
public boolean isUserMessage(String messageId) {
return messageId.startsWith("MSG_"); // 重复的判断逻辑
}
}
// ✅ 值对象包含业务行为
public class MessageId extends BaseId {
public boolean isSystemMessage() {
return value.startsWith("SYS_");
}
public boolean isUserMessage() {
return value.startsWith("MSG_");
}
public MessageType getType() {
if (isSystemMessage()) return MessageType.SYSTEM;
if (isUserMessage()) return MessageType.USER;
return MessageType.UNKNOWN;
}
}
// 使用时更自然
if (messageId.isSystemMessage()) {
// 处理系统消息
}7️⃣ 更好的测试性(Testability)
// ❌ 测试时需要记住格式
@Test
public void testSendMessage() {
String messageId = "MSG_123456"; // 需要知道格式
String userId = "USER_789"; // 容易写错
service.sendMessage(messageId, userId);
}
// ✅ 测试更清晰
@Test
public void testSendMessage() {
MessageId messageId = MessageId.generate(); // 自动生成有效ID
UserId userId = UserId.of("USER_789"); // 验证在构造时完成
service.sendMessage(messageId, userId);
// 还可以测试值对象本身
assertTrue(messageId.isUserMessage());
}实际收益对比
让我用一个完整的例子展示收益:
场景:转账功能
// ========================================
// ❌ 使用原始类型(String)
// ========================================
public class TransferService {
public void transfer(
String fromAccountId,
String toAccountId,
String amount,
String currency
) {
// 问题1:需要大量验证代码
if (fromAccountId == null || fromAccountId.isEmpty()) {
throw new IllegalArgumentException("源账户ID不能为空");
}
if (!fromAccountId.matches("^ACC_\\d{10}$")) {
throw new IllegalArgumentException("源账户ID格式错误");
}
// 问题2:重复验证
if (toAccountId == null || toAccountId.isEmpty()) {
throw new IllegalArgumentException("目标账户ID不能为空");
}
if (!toAccountId.matches("^ACC_\\d{10}$")) {
throw new IllegalArgumentException("目标账户ID格式错误");
}
// 问题3:业务规则散落
if (fromAccountId.equals(toAccountId)) {
throw new IllegalArgumentException("不能转账给自己");
}
// 问题4:金额处理复杂
BigDecimal amountValue = new BigDecimal(amount);
if (amountValue.compareTo(BigDecimal.ZERO) <= 0) {
throw new IllegalArgumentException("金额必须大于0");
}
// 实际业务逻辑淹没在验证代码中
doTransfer(fromAccountId, toAccountId, amountValue, currency);
}
}
// ========================================
// ✅ 使用值对象
// ========================================
public class TransferService {
public void transfer(
AccountId fromAccountId,
AccountId toAccountId,
Money amount
) {
// 不需要验证,值对象保证有效性
// 业务规则清晰
if (fromAccountId.equals(toAccountId)) {
throw new IllegalArgumentException("不能转账给自己");
}
// 业务逻辑清晰可见
doTransfer(fromAccountId, toAccountId, amount);
}
}
// 值对象封装了所有验证
public class AccountId extends BaseId {
public AccountId(String value) {
super(value);
if (!value.matches("^ACC_\\d{10}$")) {
throw new IllegalArgumentException("账户ID格式错误");
}
}
}
public class Money {
private final BigDecimal amount;
private final Currency currency;
public Money(BigDecimal amount, Currency currency) {
if (amount.compareTo(BigDecimal.ZERO) <= 0) {
throw new IllegalArgumentException("金额必须大于0");
}
this.amount = amount;
this.currency = currency;
}
// 业务行为
public Money add(Money other) { ... }
public Money subtract(Money other) { ... }
public boolean isGreaterThan(Money other) { ... }
}这不是过度设计的理由
✅ 值对象的投资回报率(ROI)
| 投入 | 回报 |
|---|---|
| 创建一个值对象类(50行代码) | 消除数百处验证代码 |
| 定义清晰的类型 | 编译期发现99%的类型错误 |
| 封装业务规则 | 规则修改只需改一处 |
| 一次性设计 | 整个项目生命周期受益 |
❌ 什么时候是过度设计?
// 这是过度设计
public class FirstName extends BaseId { ... }
public class LastName extends BaseId { ... }
public class MiddleName extends BaseId { ... }
// 这样就够了
public class PersonName {
private String firstName;
private String lastName;
private String middleName;
}判断标准:
✅ 需要值对象:ID、金额、邮箱、电话号码、地址等有验证规则的
❌ 不需要值对象:简单的描述性字符串、没有业务规则的字段
总结:为什么 ID 要设计成值对象
| 问题 | 原始类型(String/Long) | 值对象(MessageId) |
|---|---|---|
| 类型安全 | ❌ 编译器无法检测错误 | ✅ 编译期类型检查 |
| 验证 | ❌ 到处重复验证 | ✅ 一处验证,处处有效 |
| 业务语义 | ❌ 看不出业务含义 | ✅ 清晰表达业务概念 |
| 不可变性 | ❌ 可以被修改 | ✅ 天然不可变 |
| 业务行为 | ❌ 只是数据 | ✅ 可以包含行为 |
| 重构安全 | ❌ 全局搜索替换 | ✅ 编译器辅助重构 |
| 测试 | ❌ 需要记住格式 | ✅ 自动生成有效值 |
核心价值
// 值对象让代码从这样:
public void like(String s1, String s2) {
if (s1 == null || s1.isEmpty()) { ... }
if (s2 == null || s2.isEmpty()) { ... }
// 业务逻辑
}
// 变成这样:
public void like(UserId userId, PostId postId) {
// 直接写业务逻辑,清晰、安全、优雅
}这不是过度设计,这是正确的设计! 🎯
在 DDD 中,值对象是战术设计的核心模式之一,与实体(Entity)、聚合(Aggregate)并列为三大基础构建块。你的项目使用值对象来表示 ID,是完全符合 DDD 最佳实践的!
值对象 UserId三种调用方式
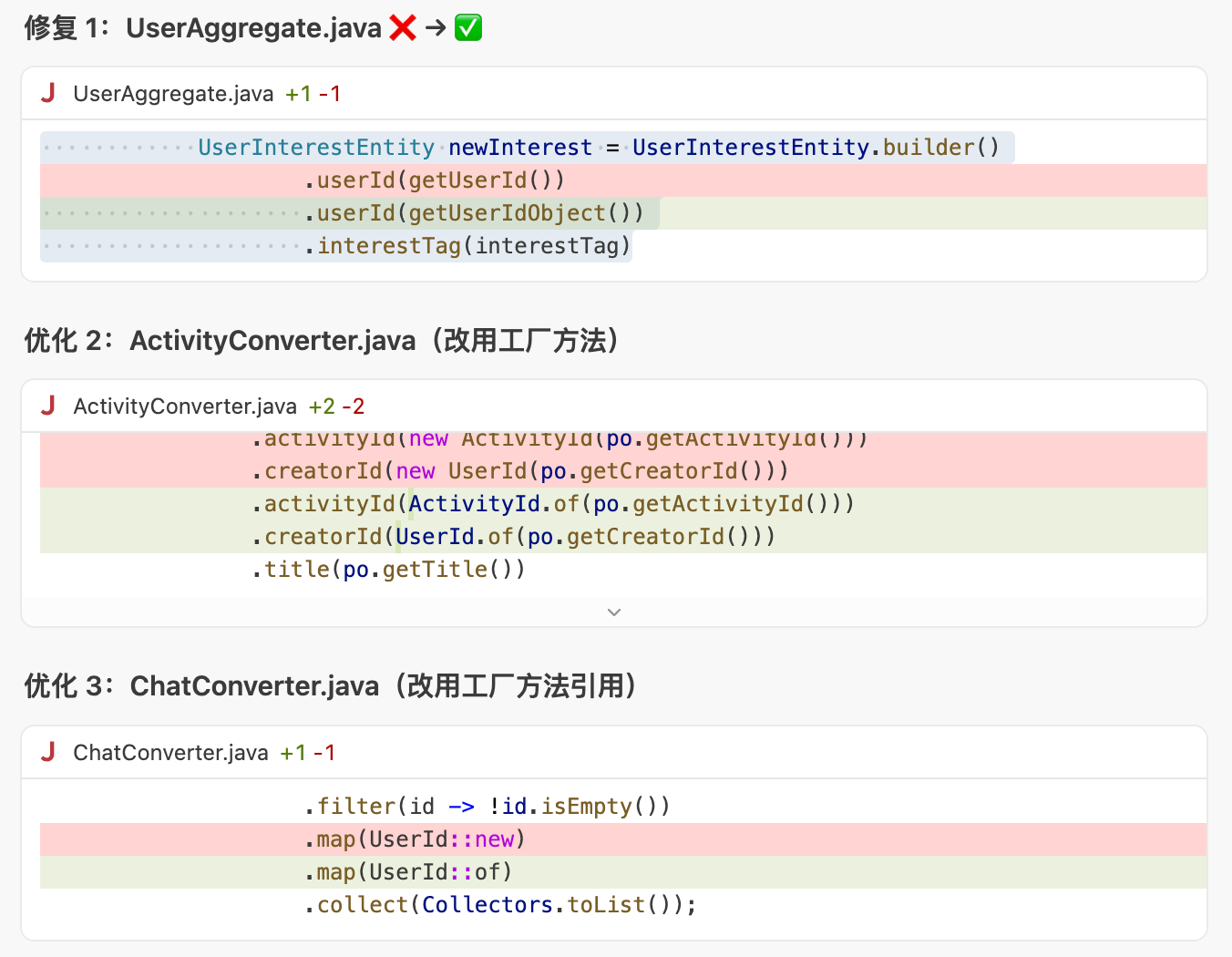
1️⃣ ActivityConverter.java (124) - ✅ 正确但不推荐
.creatorId(new UserId(po.getCreatorId()))分析:
使用 new UserId(String) 构造函数
✅ 可以工作
⚠️ 不推荐:直接使用构造函数不如使用工厂方法
2️⃣ ChatConverter.java (79-86) - ✅ 正确但不推荐
participantIds = Arrays.stream(po.getParticipantIds().split(","))
.map(String::trim)
.filter(id -> !id.isEmpty())
.map(UserId::new) // 方法引用,等同于 new UserId(id)
.collect(Collectors.toList());分析:
使用 UserId::new 方法引用
✅ 可以工作
⚠️ 不推荐:同样是直接使用构造函数
3️⃣ UserAggregate.java (185) - ❌ 错误!
UserInterestEntity newInterest = UserInterestEntity.builder()
.userId(getUserId()) // ❌ 问题在这里!
.interestTag(interestTag)
.interestLevel(level)
.build();问题分析:
// UserAggregate 中的方法
public String getUserId() { // ❌ 返回 String
return userId != null ? userId.getValue() : null;
}
public UserId getUserIdObject() { // ✅ 返回 UserId
return userId;
}
// UserInterestEntity 的字段定义
private UserId userId; // 需要 UserId 类型
// 错误的调用
.userId(getUserId()) // ❌ 传入 String,但需要 UserId为什么有这么多调用方式?
UserId 提供了三种创建方式:
public class UserId extends BaseId {
// 方式1:构造函数(public)
public UserId(String value) {
super(value);
}
// 方式2:静态工厂方法 - of
public static UserId of(String value) {
return new UserId(value);
}
// 方式3:静态工厂方法 - generate
public static UserId generate() {
return new UserId(generateUUID());
}
}推荐的使用方式
| 场景 | 推荐方式 | 原因 |
|---|---|---|
| 从已知 String 创建 | UserId.of(string) | 语义清晰,工厂方法模式 |
| 生成新 ID | UserId.generate() | 明确表达意图 |
| Stream 转换 | UserId::of | 方法引用更清晰 |
修复方案
推荐使用方式对照表
| 场景 | ❌ 不推荐 | ✅ 推荐 | 原因 |
|---|---|---|---|
| 从 String 创建 | new UserId(str) | UserId.of(str) | 工厂方法语义更清晰 |
| 生成新 ID | new UserId(UUID...) | UserId.generate() | 意图明确 |
| Stream 转换 | UserId::new | UserId::of | 统一使用工厂方法 |
| Builder 中使用 | .userId(string) | .userId(UserId.of(string)) | 类型正确 |
🎯 为什么要统一使用工厂方法?
1. 语义清晰
// 正确代码
UserInterestEntity newInterest = UserInterestEntity.builder()
.userId(getUserIdObject()) // ✅ 返回 UserId 对象
.build();2. 便于扩展
// UserId 提供的三种创建方式
public class UserId extends BaseId {
// 1. 构造函数(不推荐直接使用)
public UserId(String value) { ... }
// 2. 静态工厂方法 - of(推荐)
public static UserId of(String value) {
return new UserId(value);
}
// 3. 静态工厂方法 - generate(推荐)
public static UserId generate() {
return new UserId(generateUUID());
}
}3. 统一代码风格
// 修复前
.userId(getUserId()) // ❌ String 类型
// 修复后
.userId(getUserIdObject()) // ✅ UserId 类型4. 更好的可读性
// 优化前
.creatorId(new UserId(po.getCreatorId())) // ⚠️ 可用但不推荐
// 优化后
.creatorId(UserId.of(po.getCreatorId())) // ✅ 推荐方式🔧 设计模式:静态工厂方法的优势
这是《Effective Java》第1条建议:考虑用静态工厂方法代替构造器
// 优化前
.map(UserId::new) // ⚠️ 可用但不推荐
// 优化后
.map(UserId::of) // ✅ 推荐方式📊 修复效果对比
| 指标 | 修复前 | 修复后 |
|---|---|---|
| 类型安全 | ❌ UserAggregate 类型错误 | ✅ 所有类型正确 |
| 代码一致性 | ❌ 三种不同调用方式 | ✅ 统一使用工厂方法 |
| 可维护性 | ⚠️ 混乱的调用方式 | ✅ 清晰的代码规范 |
| 可读性 | ⚠️ 意图不明确 | ✅ 语义清晰 |
💡 总结
1.核心问题:UserAggregate 中 getUserId() 返回 String,但 UserInterestEntity 需要 UserId 对象
2.次要问题:项目中混用了构造函数和工厂方法,代码风格不统一
3.解决方案:
修复类型错误:使用 getUserIdObject() 而不是 getUserId()
统一代码风格:全部使用 UserId.of() 工厂方法
4.最佳实践:始终使用静态工厂方法(UserId.of() 或 UserId.generate())而不是直接调用构造函数
这样的修复不仅解决了编译错误,还提升了代码质量和一致性!🎯
聚合根 UserAggregate 为什么要单独定义值对象 UserId
@UserAggregate.java (56-68) 为什么在这个聚合根里面还要单独判断UserId 是否为空,刚刚我们聊到 充血模型里面的值对象,UserId extend BaseId 就已经实现了一些空值判断,那为什么这里的聚合根不用 UserId 里面自带的值判断,反而重新定义了,这又是 DDD 中哪一环设计,你说明下
DDD 设计原理分析
问题核心:两层防御
// 第一层防御:UserId 值对象(内部验证)
public class UserId extends BaseId {
public UserId(String value) {
super(value);
// BaseId 中的验证
if (value == null || value.trim().isEmpty()) {
throw new IllegalArgumentException("ID值不能为空");
}
}
}
// 第二层防御:UserAggregate 聚合根(外部验证)
public class UserAggregate {
private UserId userId; // 可能为 null!
public String getUserId() {
return userId != null ? userId.getValue() : null; // 为什么要判空?
}
}为什么需要两层判断?这是 DDD 的哪个设计?
1️⃣ 聚合根的生命周期管理
这涉及到 DDD 中聚合根(Aggregate Root)的完整生命周期:
// 场景1:聚合根正在构建中(不完整状态)
UserAggregate aggregate = UserAggregate.builder()
// .userId(UserId.of("USER_123")) // ❌ 忘记设置了!
.userEntity(userEntity)
.build();
// 此时 aggregate.userId 为 null
String id = aggregate.getUserId(); // 如果不判空会 NPE
// 场景2:从数据库加载时可能数据不完整
UserAggregate aggregate = repository.findById("xxx");
// 数据库中的数据可能损坏或迁移过程中丢失
// 场景3:反序列化时
UserAggregate aggregate = objectMapper.readValue(json, UserAggregate.class);
// JSON 中可能缺少某些字段关键点:
✅ UserId 值对象保证:一旦创建,内部的 value 一定不为空
⚠️ UserAggregate 不保证:userId 字段本身可能为 null
2️⃣ 防御性编程 vs 契约式编程
这是两种不同的设计哲学在 DDD 中的体现:
A. 值对象层面:契约式编程(Design by Contract)
public class UserId extends BaseId {
public UserId(String value) {
super(value);
// 前置条件(Precondition):value 不能为空
if (value == null || value.trim().isEmpty()) {
throw new IllegalArgumentException("ID值不能为空");
}
// 后置条件(Postcondition):一旦创建成功,value 一定有效
}
public String getValue() {
// 不需要判空,因为构造函数保证了 value 不为空
return this.value;
}
}契约: 调用者必须保证传入有效的 value,值对象保证内部状态一致性。
B. 聚合根层面:防御性编程(Defensive Programming)
public class UserAggregate {
private UserId userId; // 可能为 null
public String getUserId() {
// 防御性编程:不信任对象的状态
return userId != null ? userId.getValue() : null;
}
}防御: 不假设聚合根总是处于完整状态,提供容错机制。
3️⃣ 聚合根的不变性边界(Invariant Boundary)
这是 DDD 中聚合(Aggregate)模式的核心概念。
public class UserAggregate {
private UserId userId;
private UserEntity userEntity;
// 聚合的不变性规则(Invariants)
// 规则1:userId 和 userEntity.userId 必须一致
// 规则2:聚合可以处于"不完整"状态(构建中)
// 规则3:聚合必须提供方法来验证完整性
/**
* 验证聚合是否完整
*/
public boolean isComplete() {
return userId != null &&
userEntity != null &&
userEntity.getUserId() != null;
}
/**
* 安全地获取用户ID
*/
public String getUserId() {
// 防御性返回,允许不完整状态
return userId != null ? userId.getValue() : null;
}
}4️⃣ 实际场景对比
让我用实际场景说明为什么需要这样设计:
场景A:创建新用户(Builder 模式)
// 使用 Builder 逐步构建聚合
UserAggregate.UserAggregateBuilder builder = UserAggregate.builder();
// 步骤1:设置用户实体
builder.userEntity(userEntity);
// 步骤2:还没设置 userId
// builder.userId(userId); // 忘记了!
// 步骤3:构建聚合
UserAggregate aggregate = builder.build();
// 此时 aggregate.userId 为 null
// 如果 getUserId() 不判空,会抛出 NPE
String id = aggregate.getUserId(); // 返回 null,而不是崩溃
// 步骤4:验证完整性
if (!aggregate.isComplete()) {
throw new IllegalStateException("用户聚合不完整");
}场景B:从数据库加载(可能数据损坏)
// 数据库中的数据可能不完整
UserAggregate aggregate = repository.findById("USER_123");
// 数据库迁移时可能丢失了某些字段
// 或者历史数据不符合新的业务规则
// 防御性编程允许我们优雅地处理这种情况
if (aggregate.getUserId() == null) {
log.error("用户聚合数据损坏:userId 为空");
// 可以修复数据或标记为异常
} else {
// 正常处理
}场景C:API 层的容错
@RestController
public class UserController {
@GetMapping("/users/{id}")
public UserDTO getUser(@PathVariable String id) {
UserAggregate aggregate = userService.getUser(id);
// 如果聚合不完整,可以返回部分数据
return UserDTO.builder()
.userId(aggregate.getUserId()) // 可能返回 null
.nickname(aggregate.getNickname()) // 可能返回 null
.email(aggregate.getEmail() != null ?
aggregate.getEmail().getValue() : null)
.build();
// 而不是直接崩溃
}
}5️⃣ 这是 DDD 中的哪个设计?
这个设计体现了 DDD 的多个核心概念:
A. 聚合根的职责(Aggregate Root Responsibility)
/**
* 聚合根的职责:
* 1. 维护聚合内部的一致性
* 2. 提供安全的访问接口
* 3. 处理不完整状态
* 4. 提供验证方法
*/
public class UserAggregate {
// 职责1:维护一致性
public void updateEmail(Email newEmail) {
if (userId == null) {
throw new IllegalStateException("用户ID不能为空");
}
// 更新逻辑
}
// 职责2:安全访问
public String getUserId() {
return userId != null ? userId.getValue() : null;
}
// 职责3:处理不完整状态
public boolean isComplete() {
return userId != null && userEntity != null;
}
// 职责4:提供验证
public void validate() {
if (userId == null) {
throw new IllegalStateException("用户ID不能为空");
}
if (userEntity == null) {
throw new IllegalStateException("用户实体不能为空");
}
}
}B. 防腐层(Anti-Corruption Layer)
聚合根作为领域模型的边界,需要保护内部不受外部影响:
public class UserAggregate {
// 内部状态可能不完整
private UserId userId;
// 对外提供安全的接口(防腐层)
public String getUserId() {
// 不暴露内部可能的 null 引用
return userId != null ? userId.getValue() : null;
}
// 或者提供明确的异常
public String getUserIdOrThrow() {
if (userId == null) {
throw new IllegalStateException("用户ID未初始化");
}
return userId.getValue();
}
}C. 分层防御(Defense in Depth)
┌─────────────────────────────────────────┐
│ API 层(第三层防御) │
│ - 验证请求参数 │
│ - 处理 null 返回值 │
└─────────────────────────────────────────┘
↓
┌─────────────────────────────────────────┐
│ 聚合根层(第二层防御) │ ← 这里!
│ - 判断 userId 是否为 null │
│ - 提供安全的访问方法 │
│ - 验证聚合完整性 │
└─────────────────────────────────────────┘
↓
┌─────────────────────────────────────────┐
│ 值对象层(第一层防御) │
│ - 验证 value 不为空 │
│ - 保证内部状态一致性 │
└─────────────────────────────────────────┘6️⃣ 更好的设计方案
虽然当前设计是合理的,但我们可以让它更明确:
方案A:明确区分完整和不完整状态
public class UserAggregate {
private UserId userId;
/**
* 获取用户ID(可能为空)
* 用于查询场景
*/
public String getUserIdOrNull() {
return userId != null ? userId.getValue() : null;
}
/**
* 获取用户ID(保证非空)
* 用于业务操作场景
*/
public String getUserIdOrThrow() {
if (userId == null) {
throw new IllegalStateException("用户聚合未完全初始化");
}
return userId.getValue();
}
/**
* 获取用户ID值对象(可能为空)
*/
public UserId getUserIdObject() {
return userId;
}
/**
* 验证聚合是否可用于业务操作
*/
public void ensureComplete() {
if (userId == null) {
throw new IllegalStateException("用户ID未初始化");
}
if (userEntity == null) {
throw new IllegalStateException("用户实体未初始化");
}
}
}方案B:使用 Optional
public class UserAggregate {
private UserId userId;
/**
* 获取用户ID(使用 Optional 明确可能为空)
*/
public Optional<String> getUserId() {
return Optional.ofNullable(userId)
.map(UserId::getValue);
}
/**
* 获取用户ID值对象
*/
public Optional<UserId> getUserIdObject() {
return Optional.ofNullable(userId);
}
}
// 使用时
String id = aggregate.getUserId()
.orElse("UNKNOWN");
String id = aggregate.getUserId()
.orElseThrow(() -> new IllegalStateException("用户ID未初始化"));总结对比表
| 层次 | 职责 | 空值处理 | 原因 |
|---|---|---|---|
| 值对象(UserId) | 保证内部值有效 | 构造时验证,不接受 null | 一旦创建,保证有效性 |
| 聚合根(UserAggregate) | 管理聚合生命周期 | 字段可能为 null,方法判空 | 允许不完整状态,提供容错 |
| 应用服务 | 协调业务流程 | 验证聚合完整性 | 确保业务操作前状态有效 |
核心结论
// ✅ 这不是重复设计,而是分层防御
// 第一层:值对象保证内部一致性
UserId userId = UserId.of("USER_123"); // 保证 value 不为空
// 第二层:聚合根处理生命周期
UserAggregate aggregate = new UserAggregate();
aggregate.getUserId(); // 可能返回 null,因为 userId 字段可能未初始化
// 两层防御的目的不同:
// - 值对象:保证"一旦创建就有效"
// - 聚合根:允许"构建过程中的不完整状态"这是 DDD 中聚合根生命周期管理和防御性编程的最佳实践! 🎯
不是过度设计,而是对不同层次职责的清晰划分。值对象保证微观的不变性,聚合根管理宏观的生命周期。
为什么聚合根要持有 UserId 值对象?
首先基于聚合根里面为什么单独定义值对象,而不是直接使用工厂模式调用,我对 Cursor 提出了疑问:
那这样的话为什么要在聚合根里面定义值对象 UserId,直接 @ChatConverter.java (45-50) 这样获取 userId不行吗,或者 @ActivityConverter.java (124) 这样,为什么要在这里定义一个 UserId出来了 @UserAggregate.java (56-61) ,这是基于 DDD 怎样的考虑了,我感觉这只是一个对象的实例化,为什么弄出这么多形式,既然你说通过工厂模式创建对象,那为什么还要重复声明 UserId 对象了核心问题:为什么聚合根要持有 UserId 值对象?
对比:两种设计方案
❌ 方案A:聚合根只用 String(你的疑问)
public class UserAggregate {
private String userId; // 直接用 String
public String getUserId() {
return userId; // 直接返回
}
}
// 使用时
UserAggregate aggregate = repository.findById("USER_123");
String id = aggregate.getUserId(); // 直接拿到 String
// Converter 中
po.setCreatorId(aggregate.getUserId()); // 直接用 String看起来很简单,为什么不这样做?
✅ 方案B:聚合根持有值对象(当前设计)
public class UserAggregate {
private UserId userId; // 持有值对象
public String getUserId() {
return userId != null ? userId.getValue() : null;
}
public UserId getUserIdObject() {
return userId; // 返回值对象
}
}
// 使用时
UserAggregate aggregate = repository.findById("USER_123");
UserId userIdObj = aggregate.getUserIdObject(); // 拿到值对象
String id = aggregate.getUserId(); // 或者拿到 StringDDD 核心原理:领域模型的纯粹性
1️⃣ 领域层不应该依赖基础设施层的概念
这是 DDD 分层架构的核心原则:
┌─────────────────────────────────────────┐
│ 基础设施层 (Infrastructure) │
│ - PO (Persistence Object) │
│ - Converter (转换器) │
│ - 知道如何存储到数据库 │
│ - String userId 是数据库的表示 │
└─────────────────────────────────────────┘
↑ 依赖
┌─────────────────────────────────────────┐
│ 领域层 (Domain) │ ← 核心!
│ - Aggregate (聚合根) │
│ - UserId (值对象) │
│ - 不知道数据库的存在 │
│ - UserId 是业务概念的表示 │
└─────────────────────────────────────────┘关键点: 领域层应该用业务语言(UserId),而不是技术语言(String)
2️⃣ 类型安全:编译期保护
让我用实际场景说明为什么需要类型安全:
场景:转账功能
// ❌ 使用 String:容易出错
public class UserAggregate {
private String userId;
private String accountId;
private String sessionId;
}
public void transfer(UserAggregate from, UserAggregate to, String amount) {
// 问题:所有都是 String,容易混淆
bankService.transfer(
from.getAccountId(), // 应该传 accountId
to.getUserId(), // ❌ 错误!传了 userId
amount
);
// 编译通过,运行时才发现错误!
}
// ✅ 使用值对象:编译期检查
public class UserAggregate {
private UserId userId;
private AccountId accountId;
private SessionId sessionId;
}
public void transfer(UserAggregate from, UserAggregate to, Money amount) {
bankService.transfer(
from.getAccountId(), // AccountId 类型
to.getUserId(), // ❌ 编译错误!类型不匹配
amount
);
// 编译器会立即报错,无法通过编译
}3️⃣ 业务规则的封装:不仅仅是数据
值对象不只是数据容器,还包含业务行为:
// ❌ String 没有业务行为
public class UserAggregate {
private String userId;
public boolean isSystemUser() {
// 业务逻辑散落在聚合根中
return userId != null && userId.startsWith("SYS_");
}
public boolean canAccessAdminPanel() {
// 又是一个判断逻辑
return userId != null && userId.startsWith("ADMIN_");
}
}
// ✅ UserId 封装业务行为
public class UserId extends BaseId {
public boolean isSystemUser() {
return value.startsWith("SYS_");
}
public boolean isAdminUser() {
return value.startsWith("ADMIN_");
}
public UserType getUserType() {
if (isSystemUser()) return UserType.SYSTEM;
if (isAdminUser()) return UserType.ADMIN;
return UserType.NORMAL;
}
}
public class UserAggregate {
private UserId userId;
public boolean canAccessAdminPanel() {
// 业务逻辑在值对象中,聚合根只是调用
return userId != null && userId.isAdminUser();
}
}4️⃣ 领域完整性:聚合根的自包含性
聚合根应该是自包含的业务概念,而不是数据传输对象:
// ❌ 贫血模型:只是数据容器
public class UserAggregate {
private String userId;
private String email;
private String phone;
// 只有 getter/setter,没有业务逻辑
}
// 外部需要知道业务规则
if (user.getUserId().startsWith("SYS_")) {
// 业务逻辑在外部
}
// ✅ 充血模型:包含业务逻辑
public class UserAggregate {
private UserId userId; // 值对象
private Email email; // 值对象
private PhoneNumber phone; // 值对象
// 业务方法
public boolean canSendMessage(UserAggregate recipient) {
// 业务规则:系统用户不能发送消息给普通用户
if (this.userId.isSystemUser() && !recipient.getUserId().isSystemUser()) {
return false;
}
return true;
}
public void updateEmail(Email newEmail) {
// 业务规则:不能使用系统邮箱
if (newEmail.isSystemEmail()) {
throw new IllegalArgumentException("不能使用系统邮箱");
}
this.email = newEmail;
}
}5️⃣ 实际场景对比
让我用一个完整的业务场景说明差异:
场景:用户匹配功能
// ❌ 使用 String:业务逻辑分散
public class MatchingService {
public boolean canMatch(UserAggregate user1, UserAggregate user2) {
String id1 = user1.getUserId();
String id2 = user2.getUserId();
// 规则1:不能和自己匹配
if (id1.equals(id2)) {
return false;
}
// 规则2:系统用户不参与匹配
if (id1.startsWith("SYS_") || id2.startsWith("SYS_")) {
return false;
}
// 规则3:测试用户只能和测试用户匹配
boolean isTest1 = id1.startsWith("TEST_");
boolean isTest2 = id2.startsWith("TEST_");
if (isTest1 != isTest2) {
return false;
}
return true;
}
}
// ✅ 使用值对象:业务逻辑清晰
public class UserId extends BaseId {
public boolean isSystemUser() {
return value.startsWith("SYS_");
}
public boolean isTestUser() {
return value.startsWith("TEST_");
}
public boolean canMatchWith(UserId other) {
// 不能和自己匹配
if (this.equals(other)) {
return false;
}
// 系统用户不参与匹配
if (this.isSystemUser() || other.isSystemUser()) {
return false;
}
// 测试用户只能和测试用户匹配
if (this.isTestUser() != other.isTestUser()) {
return false;
}
return true;
}
}
public class MatchingService {
public boolean canMatch(UserAggregate user1, UserAggregate user2) {
// 业务逻辑在值对象中,服务层只是调用
return user1.getUserIdObject().canMatchWith(user2.getUserIdObject());
}
}6️⃣ 为什么 Converter 要转换?这不是重复吗?
这是关注点分离(Separation of Concerns):
// 领域层:使用业务概念
public class UserAggregate {
private UserId userId; // 业务概念:用户身份
public UserId getUserIdObject() {
return userId;
}
}
// 基础设施层:处理持久化
public class ChatConverter {
// 从领域模型到持久化模型
public ChatPO toPO(ChatAggregate aggregate) {
ChatPO po = new ChatPO();
// 转换:业务概念 → 数据库表示
if (aggregate.getParticipantIds() != null) {
String participantIdsStr = aggregate.getParticipantIds().stream()
.map(UserId::getValue) // 值对象 → String
.collect(Collectors.joining(","));
po.setParticipantIds(participantIdsStr); // 存储为 String
}
return po;
}
// 从持久化模型到领域模型
public ChatAggregate toAggregate(ChatPO po) {
// 转换:数据库表示 → 业务概念
List<UserId> participantIds = Arrays.stream(po.getParticipantIds().split(","))
.map(String::trim)
.map(UserId::of) // String → 值对象
.collect(Collectors.toList());
return ChatAggregate.builder()
.participantIds(participantIds) // 使用值对象
.build();
}
}为什么要转换?
| 层次 | 使用的类型 | 原因 |
|---|---|---|
| 数据库 | String | 数据库只能存储基本类型 |
| 基础设施层 | String ↔️ UserId | 转换层,连接两个世界 |
| 领域层 | UserId | 业务概念,包含业务逻辑 |
7️⃣ 完整的数据流转示例
让我展示一个完整的请求流程:
// ========================================
// 1. API 层:接收 HTTP 请求
// ========================================
@RestController
public class UserController {
@PostMapping("/users/{userId}/match")
public ResponseEntity<MatchResult> matchUser(
@PathVariable String userId, // HTTP 传入 String
@RequestBody MatchRequest request
) {
// 转换为值对象
UserId userIdObj = UserId.of(userId);
UserId targetIdObj = UserId.of(request.getTargetUserId());
// 调用应用服务
MatchResult result = matchingService.match(userIdObj, targetIdObj);
return ResponseEntity.ok(result);
}
}
// ========================================
// 2. 应用层:协调业务流程
// ========================================
@Service
public class MatchingApplicationService {
public MatchResult match(UserId userId, UserId targetId) {
// 加载聚合根(包含值对象)
UserAggregate user = userRepository.findById(userId);
UserAggregate target = userRepository.findById(targetId);
// 业务逻辑(使用值对象)
if (!user.getUserIdObject().canMatchWith(target.getUserIdObject())) {
throw new BusinessException("不能匹配");
}
// 执行匹配
return domainService.performMatch(user, target);
}
}
// ========================================
// 3. 领域层:业务逻辑
// ========================================
public class UserAggregate {
private UserId userId; // 持有值对象
public UserId getUserIdObject() {
return userId;
}
}
public class UserId extends BaseId {
public boolean canMatchWith(UserId other) {
// 业务规则在这里
return !this.equals(other) &&
!this.isSystemUser() &&
!other.isSystemUser();
}
}
// ========================================
// 4. 基础设施层:数据持久化
// ========================================
public class UserRepositoryImpl implements UserRepository {
@Override
public UserAggregate findById(UserId userId) {
// 查询数据库(使用 String)
UserPO po = userMapper.selectById(userId.getValue());
// 转换为领域模型(使用值对象)
return UserConverter.toAggregate(po);
}
@Override
public void save(UserAggregate aggregate) {
// 转换为持久化模型(值对象 → String)
UserPO po = UserConverter.toPO(aggregate);
// 保存到数据库
userMapper.insert(po);
}
}
public class UserConverter {
public static UserAggregate toAggregate(UserPO po) {
return UserAggregate.builder()
.userId(UserId.of(po.getUserId())) // String → UserId
.build();
}
public static UserPO toPO(UserAggregate aggregate) {
UserPO po = new UserPO();
po.setUserId(aggregate.getUserId()); // UserId → String
return po;
}
}核心对比总结
如果聚合根只用 String
public class UserAggregate {
private String userId; // ❌
}问题:
1.❌ 失去类型安全
2.❌ 业务逻辑分散
3.❌ 领域模型退化为数据容器
4.❌ 无法表达业务概念
5.❌ 难以重构和维护
聚合根持有值对象
public class UserAggregate {
private UserId userId; // ✅
}优势:
1.✅ 编译期类型检查
2.✅ 业务逻辑封装在值对象中
3.✅ 领域模型富含业务语义
4.✅ 清晰表达业务概念
5.✅ 易于测试和维护
最终答案
为什么要在聚合根中定义 UserId 值对象?
// 这不是重复,而是分层设计
// 领域层:业务世界
public class UserAggregate {
private UserId userId; // 业务概念,包含业务规则
}
// 基础设施层:技术世界
public class UserPO {
private String userId; // 数据库表示,只是存储
}
// Converter:连接两个世界
public class UserConverter {
public static UserAggregate toAggregate(UserPO po) {
return new UserAggregate(UserId.of(po.getUserId()));
}
public static UserPO toPO(UserAggregate aggregate) {
UserPO po = new UserPO();
po.setUserId(aggregate.getUserId());
return po;
}
}这是 DDD 的哪些设计原则?
1.分层架构(Layered Architecture):领域层和基础设施层分离
2.通用语言(Ubiquitous Language):代码使用业务术语
3.充血模型(Rich Domain Model):领域对象包含行为
4.值对象(Value Object):封装业务概念和规则
5.关注点分离(Separation of Concerns):业务逻辑和持久化逻辑分离
不是重复,而是让每一层专注于自己的职责! 🎯
领域层用 UserId 表达业务,基础设施层用 String 存储数据,Converter 负责转换。这就是 DDD 的精髓!
实例演示 (简单值对象,复杂值对象)
/**
* 创建新活动
*
* @param creatorId 创建者ID
* @param title 活动标题
* @param description 活动描述
* @param activityType 活动类型
* @param startTime 开始时间
* @param endTime 结束时间
* @param location 活动地点(值对象)
* @param maxParticipants 最大参与人数
* @param costPerPerson 人均费用
* @param genderRequirement 性别要求
* @param minAge 最小年龄
* @param maxAge 最大年龄
* @return 活动实体
*/
public ActivityEntity createActivity(String creatorId, String title, String description,
String activityType, LocalDateTime startTime, LocalDateTime endTime,
Location location, Integer maxParticipants, BigDecimal costPerPerson,
String genderRequirement, Integer minAge, Integer maxAge) {
// 验证输入参数
validateActivityData(title, description, startTime, endTime, maxParticipants, costPerPerson);
// 生成活动ID
String activityId = generateActivityId();
// 创建活动实体
ActivityEntity activity = ActivityEntity.builder()
.activityId(ActivityId.of(activityId)) // 修改点:服务内生成并转换
.creatorId(UserId.of(creatorId)) // 修改点:简单转换
.title(title)
.description(description)
.activityType(activityType)
.startTime(startTime)
.endTime(endTime)
.location(location) // 修改点:直接使用值对象
.maxParticipants(maxParticipants)
.currentParticipants(1) // 创建者自动加入
.costPerPerson(costPerPerson)
.genderRequirement(genderRequirement)
.minAge(minAge)
.maxAge(maxAge)
.status("RECRUITING") // 招募中
.createTime(LocalDateTime.now())
.updateTime(LocalDateTime.now())
.build();
log.info("创建活动成功,活动ID: {}, 创建者: {}, 标题: {}", activityId, creatorId, title);
return activity;
}DDD 分层职责划分
1️⃣ 领域服务层的职责
public class ActivityCreationService {
// 领域服务接收什么?
public ActivityEntity createActivity(
String creatorId, // ✅ 接收原始类型(来自上层)
String title,
Location location, // ✅ 接收值对象(已由上层转换)
...
) {
// 领域服务的职责:
// 1. 生成业务ID
String activityId = generateActivityId();
// 2. 转换为值对象
ActivityId activityIdObj = ActivityId.of(activityId);
UserId creatorIdObj = UserId.of(creatorId);
// 3. 创建实体
return ActivityEntity.builder()
.activityId(activityIdObj) // 传入值对象
.creatorId(creatorIdObj) // 传入值对象
.location(location) // 传入值对象
.build();
}
}2️⃣ 为什么不同参数有不同的处理方式?
这取决于调用链路和职责边界:
A. activityId 和 creatorId:在服务内转换
// 为什么在服务内转换?
public ActivityEntity createActivity(
String creatorId, // 接收 String
...
) {
// 原因1:activityId 是服务内生成的
String activityId = generateActivityId(); // 生成 String
ActivityId activityIdObj = ActivityId.of(activityId); // 转换为值对象
// 原因2:creatorId 来自上层,但很简单(只是个ID)
UserId creatorIdObj = UserId.of(creatorId); // 简单转换
return ActivityEntity.builder()
.activityId(activityIdObj)
.creatorId(creatorIdObj)
.build();
}B. Location:在服务外转换(调用者转换)
// 为什么在服务外转换?
public ActivityEntity createActivity(
Location location, // 接收值对象
...
) {
// 原因1:Location 是复杂值对象,包含多个字段
// - latitude: BigDecimal
// - longitude: BigDecimal
// - address: String
// - city: String
// - province: String
// - country: String
// 原因2:转换逻辑复杂,不应该在服务内处理
// 应该由调用者(应用层)负责转换
return ActivityEntity.builder()
.location(location) // 直接使用
.build();
}3️⃣ 完整的调用链路示例
// ========================================
// 1. API 层(接收 HTTP 请求)
// ========================================
@RestController
public class ActivityController {
@PostMapping("/activities")
public ResponseEntity<ActivityDTO> createActivity(
@RequestBody CreateActivityRequest request
) {
// API 层接收原始数据
String creatorId = request.getCreatorId();
BigDecimal latitude = request.getLatitude();
BigDecimal longitude = request.getLongitude();
String address = request.getAddress();
// API 层负责转换复杂值对象
Location location = Location.of(
latitude, longitude, address,
request.getCity(), request.getProvince(), request.getCountry()
);
// 调用应用服务
ActivityEntity activity = activityApplicationService.createActivity(
creatorId, // 传 String(简单)
request.getTitle(),
request.getDescription(),
location, // 传值对象(复杂)
...
);
return ResponseEntity.ok(toDTO(activity));
}
}
// ========================================
// 2. 应用层(协调服务)
// ========================================
@Service
public class ActivityApplicationService {
public ActivityEntity createActivity(
String creatorId,
String title,
String description,
Location location, // 接收值对象
...
) {
// 应用层可以做一些验证
validateCreator(creatorId);
// 调用领域服务
return activityCreationService.createActivity(
creatorId,
title,
description,
location,
...
);
}
}
// ========================================
// 3. 领域服务层(业务逻辑)
// ========================================
@Service
public class ActivityCreationService {
public ActivityEntity createActivity(
String creatorId, // 接收 String
String title,
String description,
Location location, // 接收值对象
...
) {
// 生成 ID
String activityId = generateActivityId();
// 转换简单值对象
ActivityId activityIdObj = ActivityId.of(activityId);
UserId creatorIdObj = UserId.of(creatorId);
// 创建实体
return ActivityEntity.builder()
.activityId(activityIdObj)
.creatorId(creatorIdObj)
.location(location) // 直接使用
.build();
}
}
// ========================================
// 4. 领域实体(核心模型)
// ========================================
public class ActivityEntity {
private ActivityId activityId; // 值对象
private UserId creatorId; // 值对象
private Location location; // 值对象
}4️⃣ 设计原则总结
| 参数类型 | 接收方式 | 转换位置 | 原因 |
|---|---|---|---|
| 简单 ID (activityId, creatorId) | String | 领域服务内 | 转换简单,服务内处理 |
| 复杂值对象 (Location) | Location | 调用者(API/应用层) | 转换复杂,上层负责 |
| 生成的 ID (activityId) | 服务内生成 | 领域服务内 | 业务逻辑的一部分 |
| 外部传入的 ID (creatorId) | String | 领域服务内 | 简单转换,就近处理 |
5️⃣ 为什么这样设计?
✅ 优势
// 1. 职责清晰
// - API 层:处理复杂的数据转换
// - 领域服务:处理简单的值对象转换
// - 实体:只接收值对象
// 2. 灵活性
// - Location 可能来自不同来源(GPS、地址解析、数据库)
// - 由调用者决定如何创建 Location
// 3. 可测试性
// 测试时可以直接传入 Location 对象
ActivityEntity activity = service.createActivity(
"USER_123",
"标题",
"描述",
Location.of(BigDecimal.valueOf(39.9), BigDecimal.valueOf(116.4)),
...
);❌ 如果都在服务内转换会怎样?
// 不推荐的设计
public ActivityEntity createActivity(
String creatorId,
String title,
String description,
BigDecimal latitude, // ❌ 太多参数
BigDecimal longitude,
String address,
String city,
String province,
String country,
...
) {
// 服务内转换所有东西
Location location = Location.of(latitude, longitude, address, city, province, country);
// 问题:
// 1. 参数太多(违反单一职责)
// 2. 服务承担了转换职责
// 3. 难以测试
// 4. 不灵活
}最终结论
✅ 你的代码设计是正确的!
ActivityEntity activity = ActivityEntity.builder()
.activityId(ActivityId.of(activityId)) // ✅ 正确:服务内生成并转换
.creatorId(UserId.of(creatorId)) // ✅ 正确:简单转换
.location(location) // ✅ 正确:直接使用值对象
.build();设计原则
1.简单值对象(ID):可以在服务内转换
2.复杂值对象(Location):应该由调用者转换后传入
3.生成的值:在服务内生成并转换
4.实体构造:始终接收值对象,不接收原始类型
这完全符合 DDD 的分层架构和职责分离原则!🎯